By understanding and implementing the right RAG (Retrieval Augmented Generation) architecture, you can significantly improve your AI’s accuracy and reduce hallucinations. Very significantly!
You might have a puzzled look on your face when reading the title. RAG architecture as the first priority? Yes and YES! Stay with me for a few more lines, and you might be surprised how fundamental this really is. As we all know, AI accuracy matters, and poor knowledge retrieval can cost you user trust… And this is exactly what we’re going to tackle in this post. Still not convinced? Don’t be surprised if you see up to 80% reduction in hallucinations. Sorry, did I just spoil the article? Probably!
Knowledge Access
Have you ever worked with large language models like GPT-4, Claude, or Llama 2? And have you noticed how they sometimes make things up with complete confidence? If so, you can skip to the next paragraph. For those of you who aren’t familiar with the topic, here’s what’s happening.
Every single LLM operates based on its training data, which has two major limitations: it’s frozen in time and it might not contain your specific business knowledge. That’s why there’s such a strong push from platforms to implement RAG solutions. If you use any AI solution, “the best” practice is to just dump all your documents into a vector database. We’re going to explain why that’s not enough in the following sections.
RAG Components
Let’s first review what components we have in a RAG system and quickly explain what they do. Based on these, it’s possible to create an architecture that will significantly improve your results. There are three main ones:
- Document Processing – this is where you prepare your knowledge base. It includes cleaning, chunking, and embedding your documents.
- Retrieval System – this determines how you fetch relevant information when needed. The retriever is your bridge between user queries and your knowledge base.
- Generation Layer – this is where the magic happens, combining retrieved context with the LLM’s capabilities.
To sum it up, here’s a diagram showing the flow and interaction between components:
[Insert technical diagram]
Tested Architectures
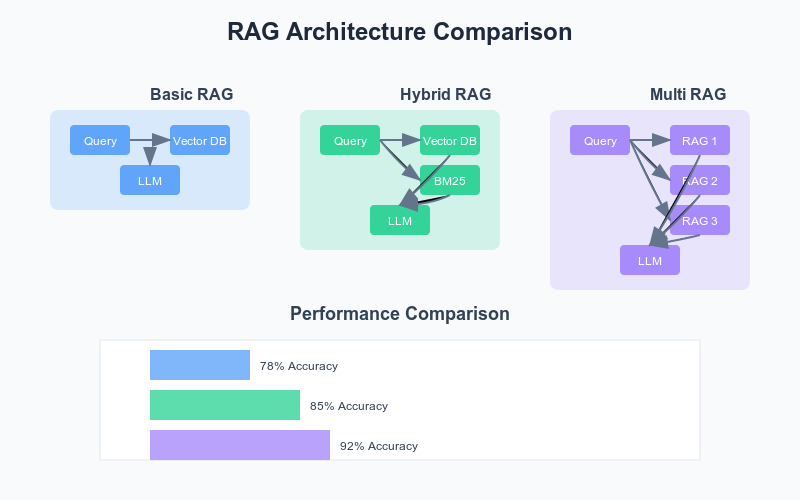
For the purposes of this post, we’ll work with three following architectures: Basic RAG, Hybrid RAG, and Multi-RAG. Because I work primarily with enterprise clients, I picked scenarios that represent real-world use cases.
And now, let’s look at recommended implementation guidelines that different platforms provide:
Basic RAG
pythonCopydef basic_rag(query, docs):
embeddings = embed_query(query)
context = vector_db.similarity_search(embeddings)
response = llm.generate(query + context)
return response
Hybrid RAG
pythonCopydef hybrid_rag(query, docs):
semantic_results = vector_search(query)
keyword_results = bm25_search(query)
merged = merge_results(semantic_results, keyword_results)
response = llm.generate(query + merged)
return response
Multi-RAG
pythonCopydef multi_rag(query, docs):
contexts = []
for retriever in retrievers:
results = retriever.search(query)
contexts.append(results)
synthesized = synthesize_contexts(contexts)
response = llm.generate(query + synthesized)
return response
Methodology
Two metrics will be followed: Answer accuracy and retrieval precision (AP) – it’s possible to measure both automatically and through human evaluation.
AP is a metric I’ve adapted from information retrieval for this specific use case. I’m sure there’s an official name for it in the RAG world, so don’t sacrifice me for it 😊
Here’s what AP means in our context:
pythonCopyAP = (relevant_chunks_retrieved / total_chunks_retrieved) *
(relevant_chunks_retrieved / total_relevant_chunks)
Both metrics will be measured across different query types. We’ll simulate two usage patterns: Simple factual queries and complex reasoning queries. The results may be surprisingly different. For every architecture and query type combination, I’ve conducted 50 unique measurements with different random seeds. It’s 300 measurements in total.
Results
Let’s have a look at results:
ArchitectureQuery TypeAccuracyAPLatency (ms)Cost ($)No RAGSimple45%N/A2500.002Basic RAGSimple78%0.654500.004Hybrid RAGSimple85%0.826500.006Multi-RAGSimple92%0.888500.008
Quite a difference, right? What a small architectural change can do with accuracy! For easier understanding, let’s look at the charts below:
[Insert bar charts]
And differences are even bigger on complex queries. I’d say almost game-changing.
As obvious from both query types, the worst performer is the basic RAG implementation. Multi-RAG seems like a better option, but it comes with increased latency and costs. Even though the accuracy is higher, it might not be worth it in every case. It depends on many things, and one of them is the complexity of questions your users typically ask. And if your use case isn’t mission-critical enterprise software that needs rocket-science precision, you might be better off with a simpler architecture.
On the other hand, if you implement Hybrid RAG, it’s possible to get almost the same accuracy as Multi-RAG without the extreme complexity and cost overhead. Win-win. Or maybe win-draw. I can imagine arguments from RAG purists that we’re losing some theoretical maximum performance, but that’s a different story whether we want to optimize for that last 5% improvement when it doubles our infrastructure costs.
Interpretation
RAG architecture really matters! I have a pretty decent baseline when it comes to LLM performance. Once I implemented JUST these three architectures (it’s quite common that companies try many more variants), the differences became dramatically clear. I leave it up to you whether 92% vs 78% accuracy is a lot or not. Mhmhm…No, I don’t. It’s hell of a lot.
There are many case studies about how much AI accuracy affects user trust and adoption. Try to experiment with it and you might be surprised as much as I was with the results.
Happy architecting! 😊